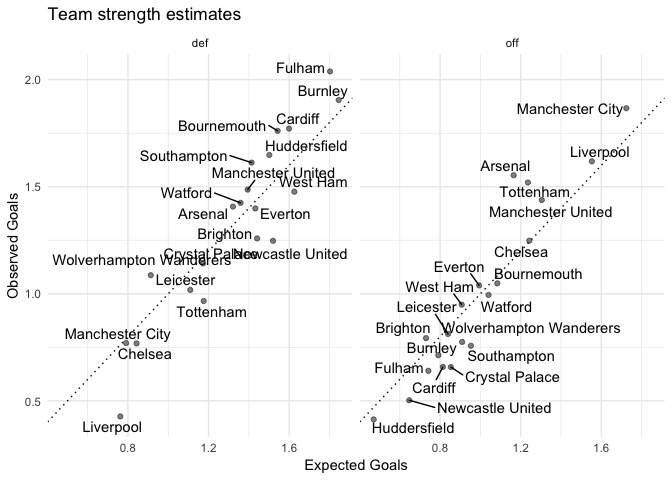
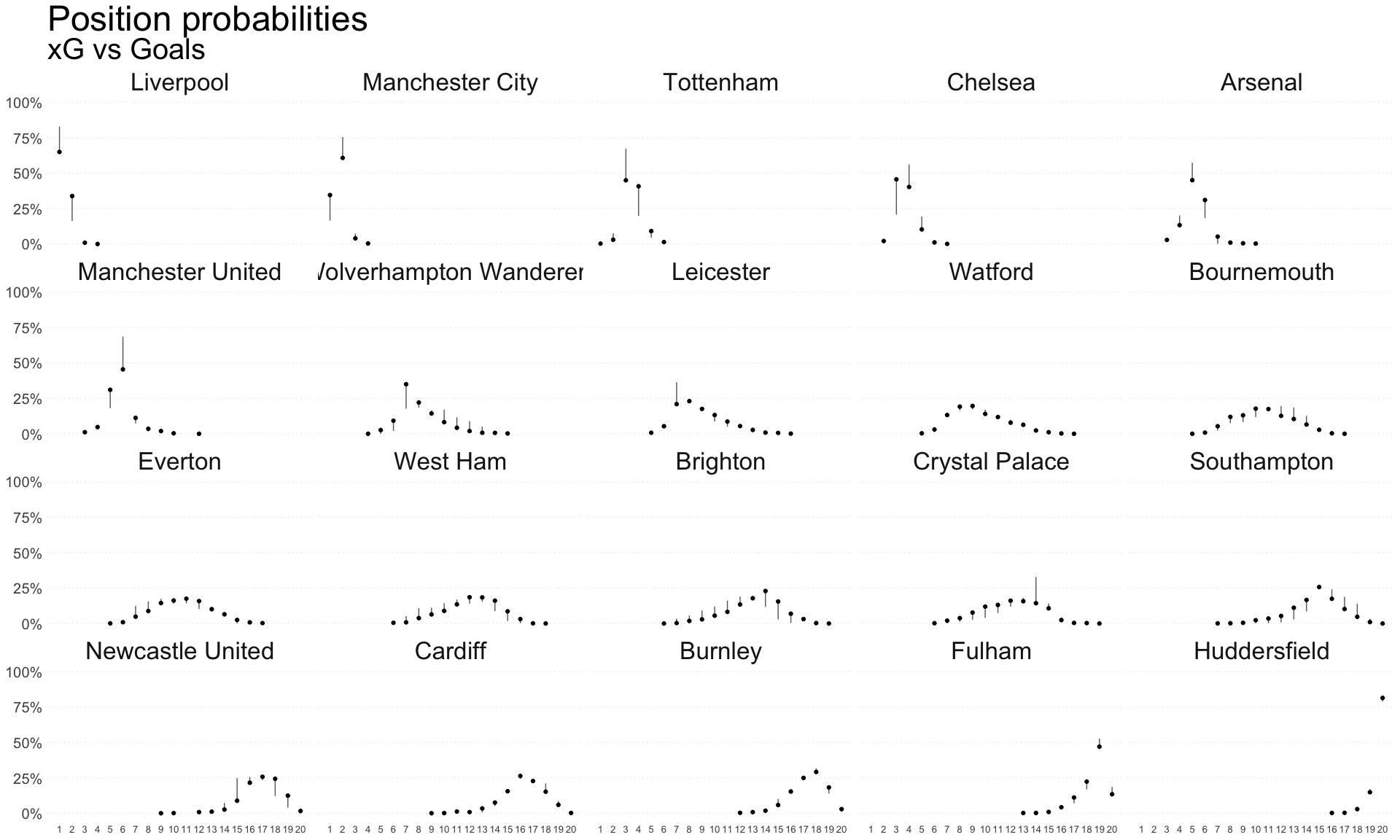
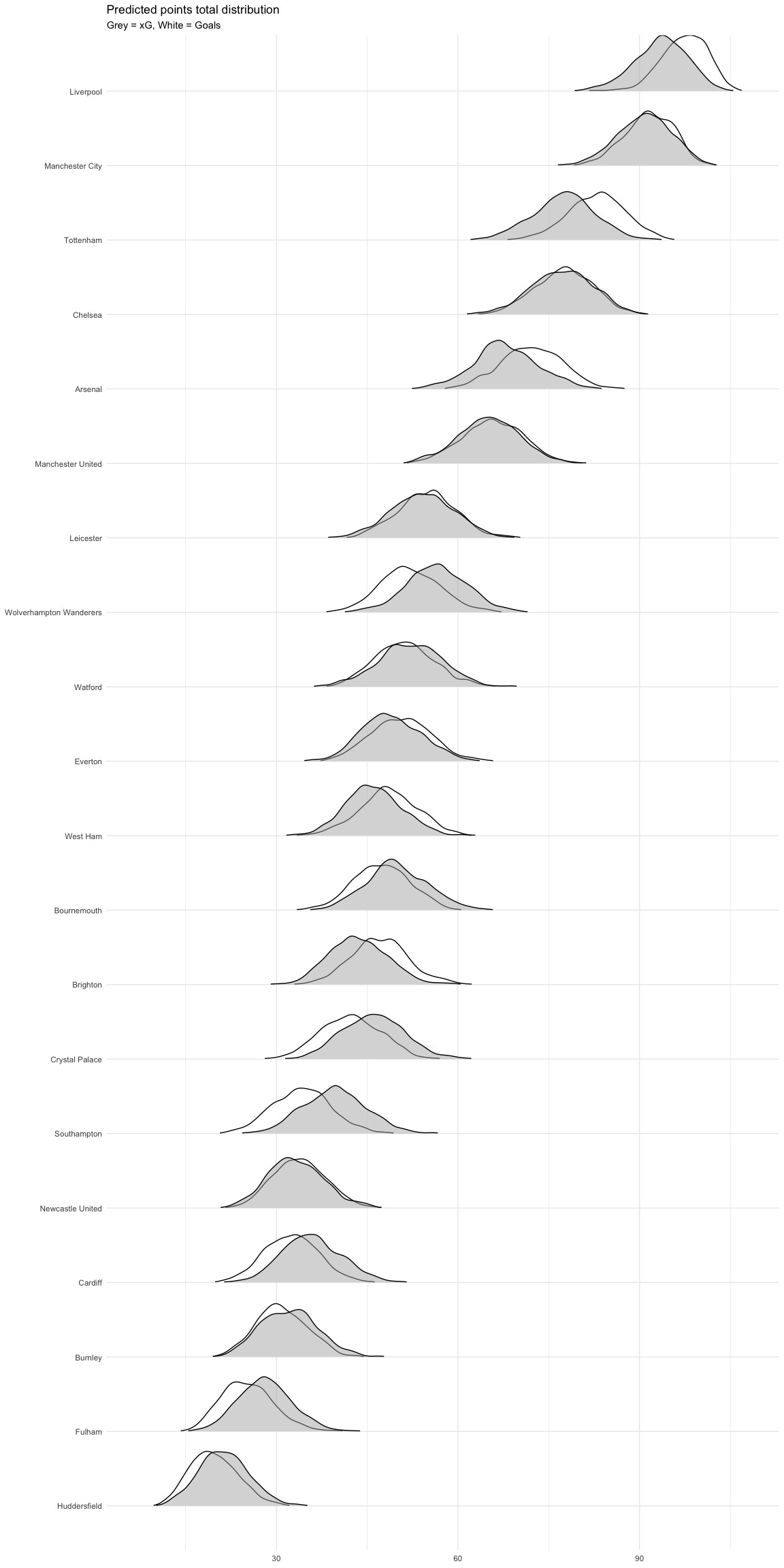
Recently, I ran through Predicting the Premier League with Dixon-Coles. I was interested in seeing how these predictions change when we use xG, rather than observed goals. So I’ve run some quick comparisons using xG data from understat.com.
The method will be largely the same as the previous post, so I’m going to keep comments on the code relatively light. If anything remains unclear, I’d suggest running through the code yourself (it should be reproducible on your computer - let me know if it’s not), or referring to the previous post.
Fetch the data
I’ll be using from understat (pasted onto GitHub), which you can access via the shortlink below:
library(tidyverse) library(regista)
data <- read_csv("https://git.io/fhsnd") %>% nest(side, xg, .key = "shots") %>% factor_teams(c("home", "away")) %>% rename(hgoal = hgoals, agoal = agoals) # Use names consistent with the previous post...
Again, this next code block is copied verbatim from another post, Dixon Coles and xG: together at last, and generates simulated scoreline probabilities from individual shot xGs.
add_if_missing <- function(data, col, fill = 0.0) { # Add column if not found in a dataframe # We need this in cases where a team has 0 shots (!) if (!(col %in% colnames(data))) { data[, col] <- fill } data }
team_goal_probs <- function(xgs, side) { # Find P(Goals=G) from a set of xGs by the poisson-binomial distribution # Use tidyeval to prefix column names with the team's side ("h"ome or "a"way) tibble(!!str_c(side, "goal") := 0:length(xgs), !!str_c(side, "prob") := poisbinom::dpoisbinom(0:length(xgs), xgs)) }
simulate_game <- function(shot_xgs) { shot_xgs %>% split(.$side) %>% imap(~ team_goal_probs(.x$xg, .y)) %>% reduce(crossing) %>% # If there are no shots, give that team a 1.0 chance of scoring 0 goals add_if_missing("hgoal", 0) %>% add_if_missing("hprob", 1) %>% add_if_missing("agoal", 0) %>% add_if_missing("aprob", 1) %>% mutate(prob = hprob * aprob) %>% select(hgoal, agoal, prob) }
simulated_games <- data %>% mutate(simulated_probabilities = map(shots, simulate_game)) %>% select(match_id, home, away, simulated_probabilities) %>% unnest() %>% filter(prob > 0.001) # Keep the number of rows vaguely reasonable
simulated_games
## # A tibble: 5,030 x 6
## match_id home away hgoal agoal prob
## <dbl> <fct> <fct> <int> <int> <dbl>
## 1 9197 Manchester United Leicester 0 0 0.00222
## 2 9197 Manchester United Leicester 1 0 0.00946
## 3 9197 Manchester United Leicester 2 0 0.00832
## 4 9197 Manchester United Leicester 3 0 0.00227
## 5 9197 Manchester United Leicester 0 1 0.0414
## 6 9197 Manchester United Leicester 1 1 0.177
## 7 9197 Manchester United Leicester 2 1 0.155
## 8 9197 Manchester United Leicester 3 1 0.0424
## 9 9197 Manchester United Leicester 4 1 0.00539
## 10 9197 Manchester United Leicester 0 2 0.0378
## # ... with 5,020 more rows
Predict the unplayed games
Work out the unplayed games
teams <- factor(levels(data$home), levels = levels(data$home))
## # A tibble: 170 x 2
## home away
## <fct> <fct>
## 1 Manchester United Watford
## 2 Manchester United Southampton
## 3 Manchester United Liverpool
## 4 Manchester United Cardiff
## 5 Manchester United West Ham
## 6 Manchester United Chelsea
## 7 Manchester United Manchester City
## 8 Manchester United Burnley
## 9 Manchester United Brighton
## 10 Newcastle United Huddersfield
## # ... with 160 more rows
## # A tibble: 37,662 x 6
## home away hgoal agoal prob model
## <fct> <fct> <int> <int> <dbl> <chr>
## 1 Manchester United Watford 0 0 0.0304 obs_goals
## 2 Manchester United Watford 1 0 0.0435 obs_goals
## 3 Manchester United Watford 2 0 0.0602 obs_goals
## 4 Manchester United Watford 3 0 0.0468 obs_goals
## 5 Manchester United Watford 4 0 0.0272 obs_goals
## 6 Manchester United Watford 5 0 0.0127 obs_goals
## 7 Manchester United Watford 6 0 0.00492 obs_goals
## 8 Manchester United Watford 7 0 0.00164 obs_goals
## 9 Manchester United Watford 8 0 0.000477 obs_goals
## 10 Manchester United Watford 9 0 0.000123 obs_goals
## # ... with 37,652 more rows
simulated_tables <- rerun(n_simulations, simulate_games(scorelines)) %>% # We need to nest the data so that we can calculate tables for # xG and G separately map(~ nest(., -model, .key = "scoreline")) %>% bind_rows(.id = "simulation_id") %>% mutate(table = map(scoreline, calculate_table)) %>% unnest(table, .drop = TRUE)
## # A tibble: 2 x 3
## team exp_goals obs_goals
## <fct> <dbl> <dbl>
## 1 Liverpool 0.65 0.829
## 2 Manchester City 0.346 0.166
There are fewer big changes in the relegation probablities, but Cardiff and Southampton are probably the biggest winners, while things look more precarious for Burnley and Newcastle:
## # A tibble: 6 x 3
## team exp_goals obs_goals
## <fct> <dbl> <dbl>
## 1 Liverpool 1 1
## 2 Manchester City 1 1
## 3 Tottenham 0.893 0.953
## 4 Chelsea 0.882 0.776
## 5 Arsenal 0.164 0.239
## 6 Manchester United 0.06 0.032
Points totals
We can see how the distribution of points totals changes. The white distribution represents the estimates based on goals, while the grey one refers to those based on xG.
The xG-based model is less keen on Liverpool’s chances of meeting 100 points. The goal-based model’s dropped its probability by about 10% points since before the Man City game