How to count minutes played
What is the best way to count minutes played based on event-data, like you might get from Opta StatsPerform, Wyscout, or StatsBomb?
It may seem like a trivial task, but it’s also a fundamental task which underpins both basic and sophisticated analytics. Mistakes in minutes played calculations can be particularly pernicious because:
- They aren’t always obvious
- They propagate to downstream calculations (e.g. p90 stats)
- They can be difficult to identify automatically and debug
With this in mind, when I recently has a chance to revisit some minutes played calculations, I wanted to take the time to find The Right Way to do it. I am happy with the solution I have found; although I would love to hear feedback from other sports analytics practitioners to see how this method might be improved.
The method
Let’s say we want to calculate minutes played for each player, with subtotals for time played in each position. The basic outline of the proposed method goes something like this:
First, arrange the events from a given match in sequence order:
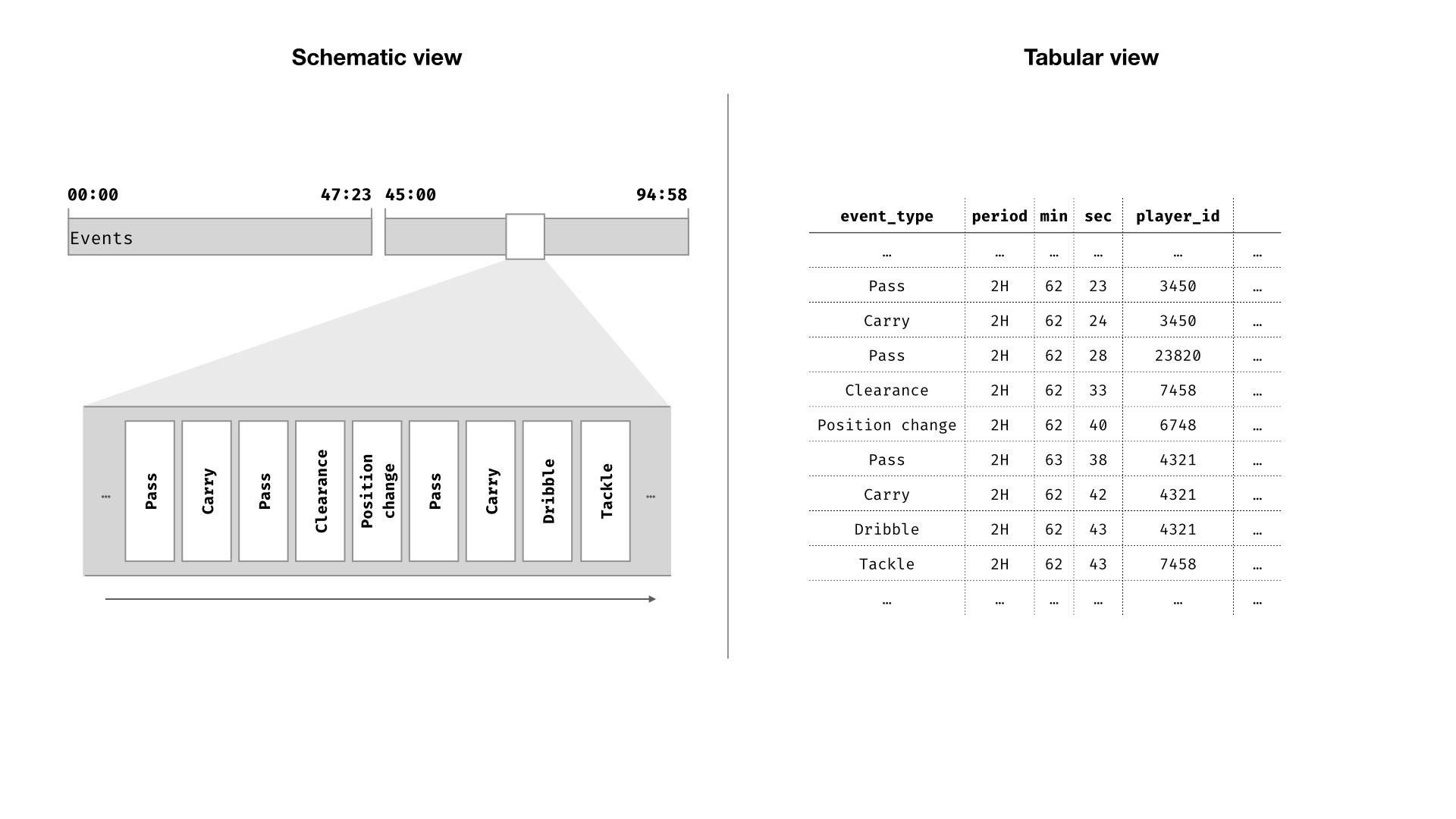
I have shown diagrams in both a “schematic” and “tabular” view. These are equivalent views on the same idea. In the schematic diagram I am trying to convey the basic concept. In the tabular form, I am trying to show something a little closer to how you might do such a transformation in a relational database, or with pandas, dplyr, or such like.
Next, identify any events that result in a change to one of the relevant match conditions. For example, a change in formation, or a goal.
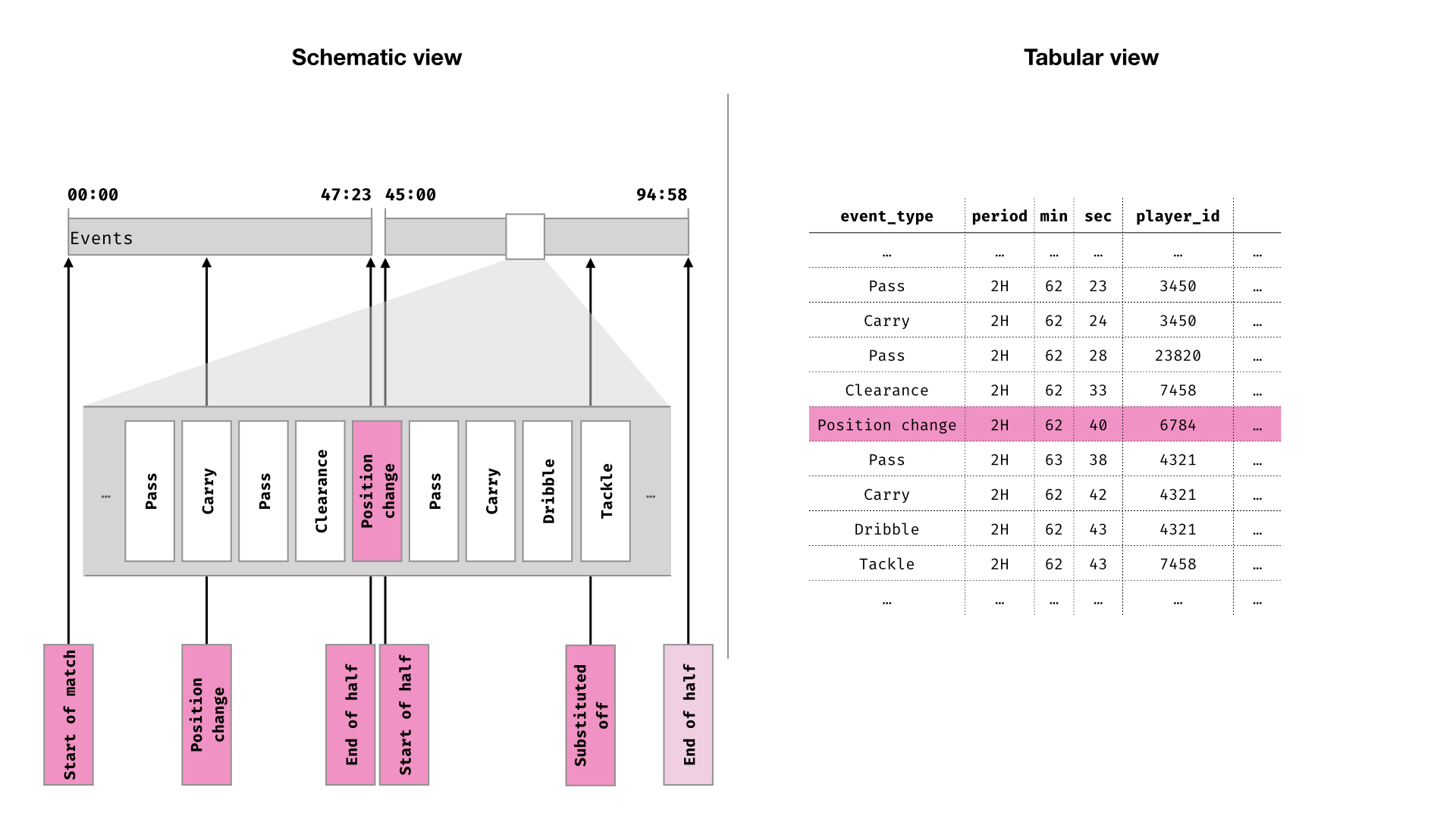
…And filter out any irrelevant events
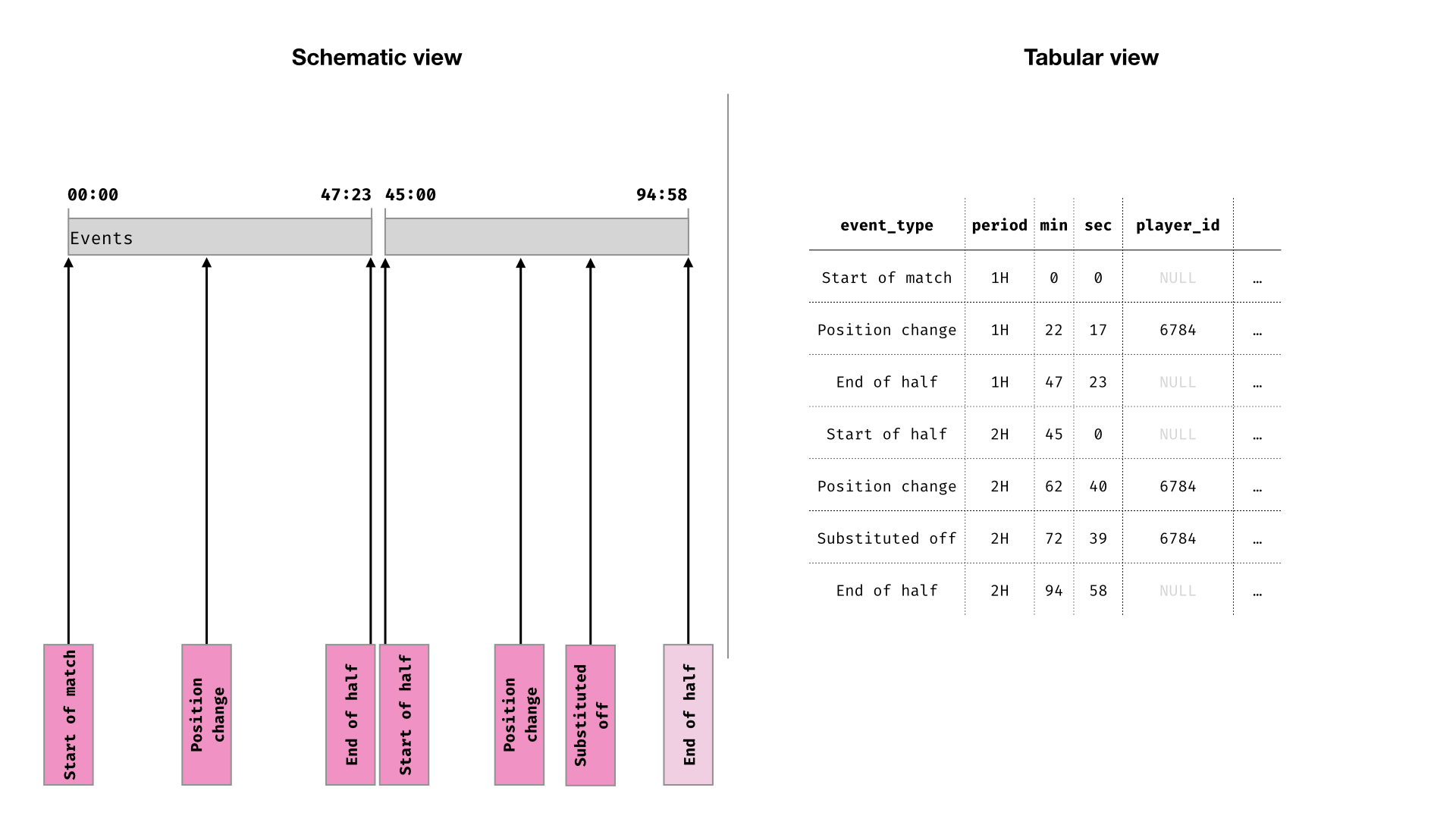
Then, construct time-windows, using the successive events as start and end points
In practice this will probably require you to infer some information from preceding or following rows. For example, you may have to infer that a player started the second half from the fact that they started the match and were not substituted or sent off.
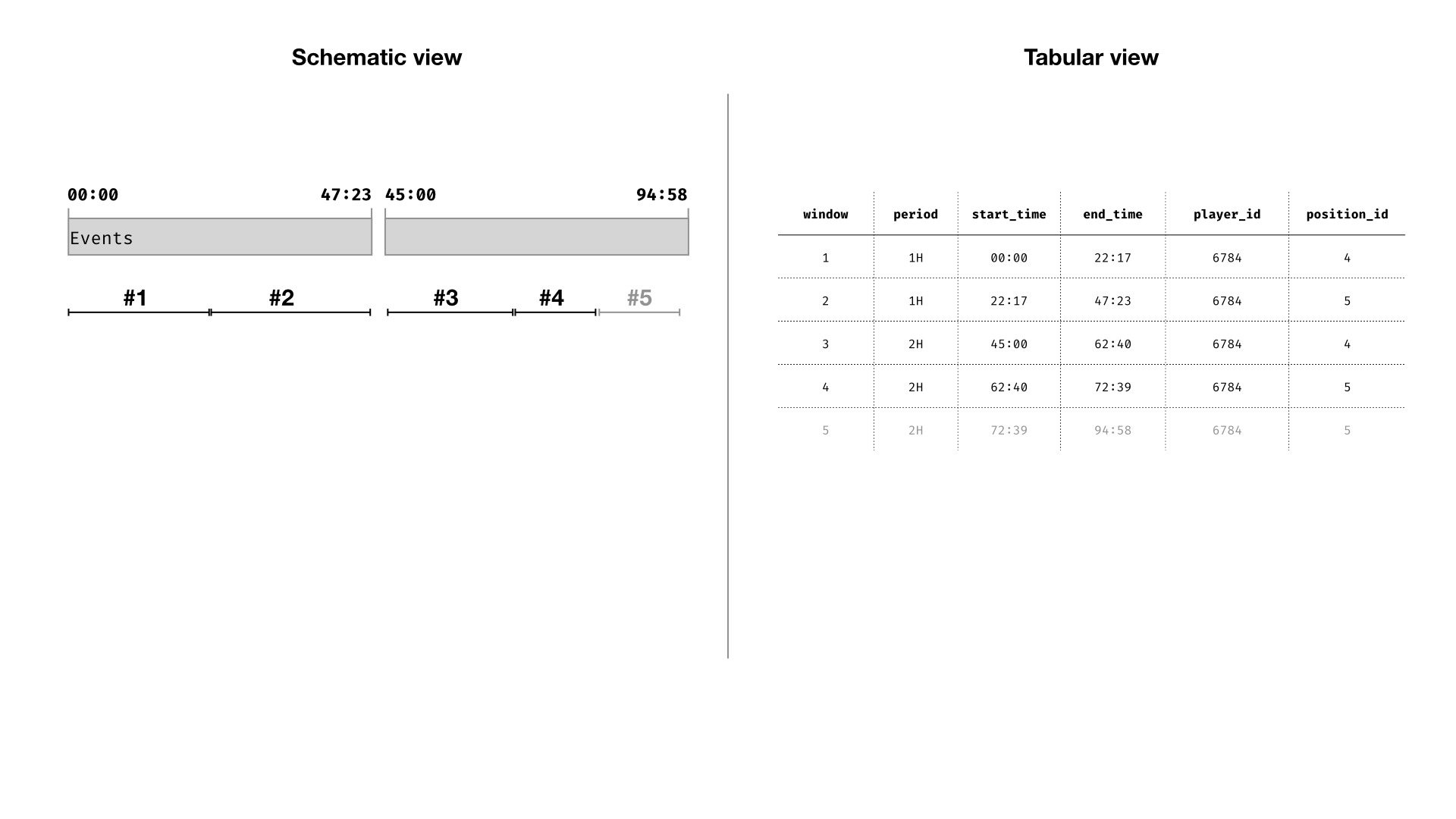
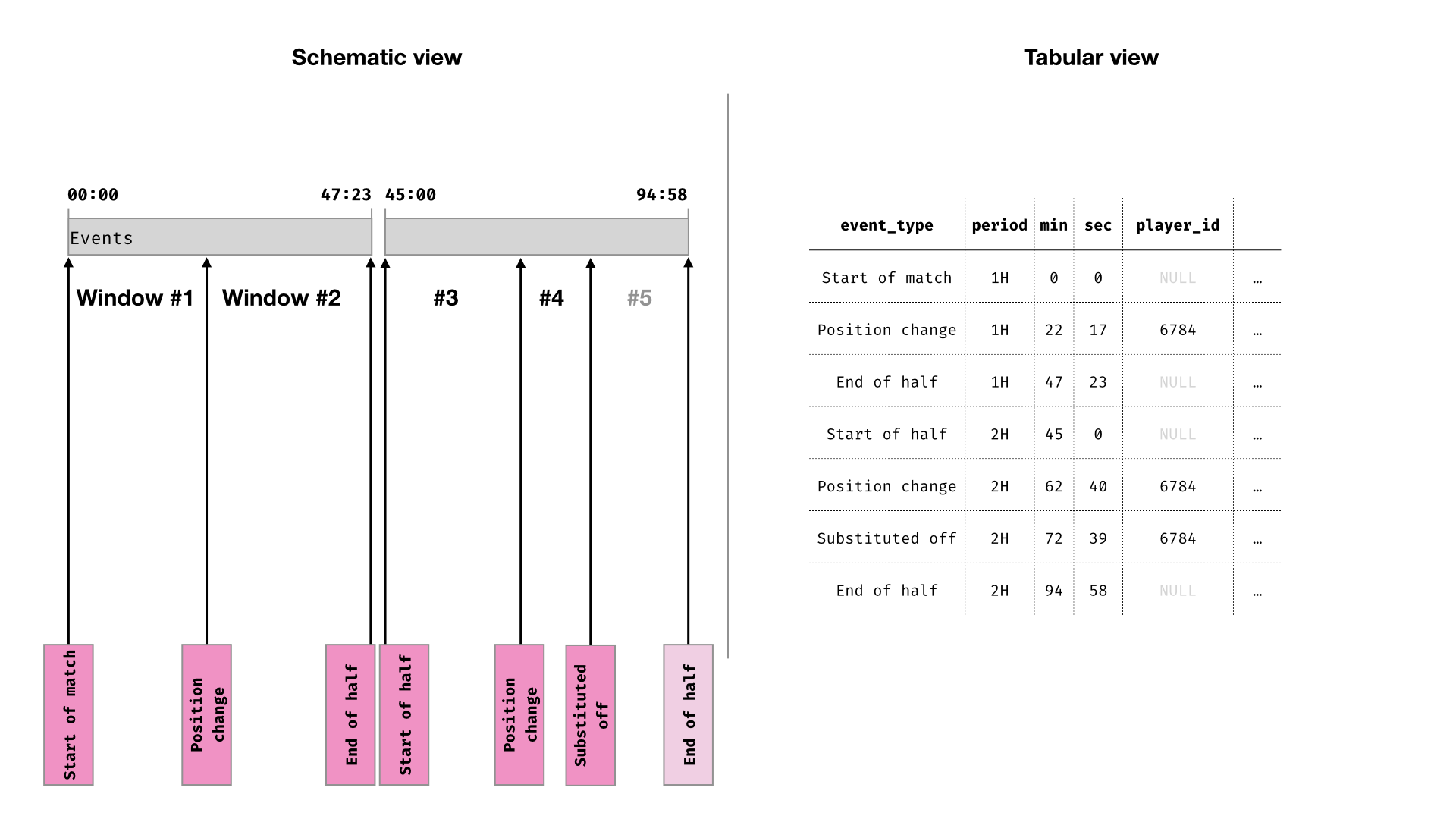
Finally, aggregate the time within each window (grouped by player and match condition). Window #5 is ignored (duration is NULL) because it takes place after the player was substituted.
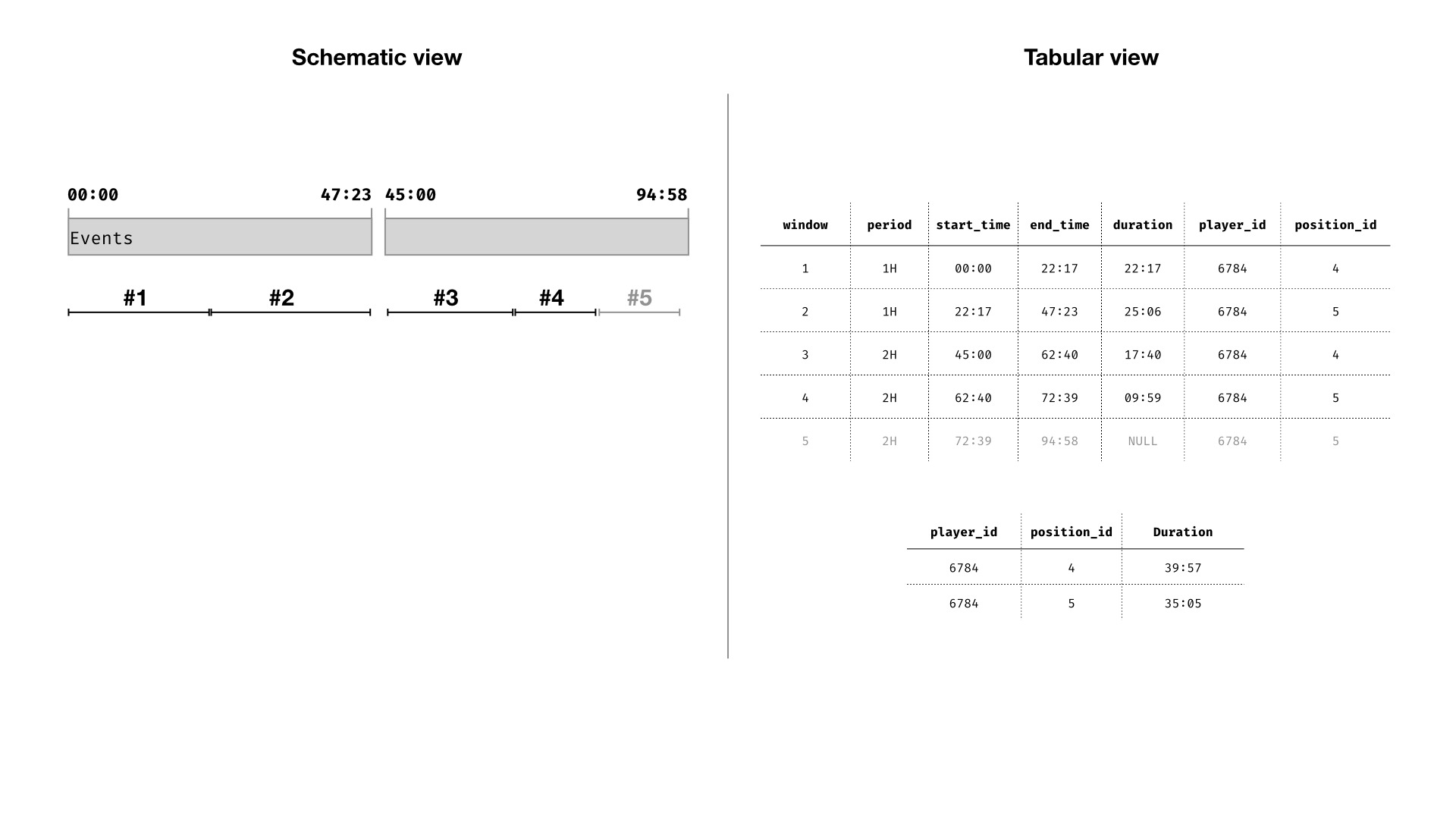
This method can be extended to calculate minutes played according to any match condition you might be interested in. For example, each player’s minutes played in a certain position, or minutes played while the team is losing.
What’s so good about this method?
You may still think that minutes played is a trivial calculation; just find the difference between the time a player came off the pitch, and the time a player came onto the pitch. And yes, this is basically true. However, going through the hassle of calculating time windows like this has a few significant benefits:
- We can slice minutes played to any grain that we want
- The intermediate time windows are useful - they allow you to get all the events from those windows, too
- It works with any event-data provider and isn’t beholden to the quirks of any one particular data collection process
An additional nice feature of this method, is that if you feel comfortable with window functions, it can be expressed relatively cleanly in pure SQL (if that’s your thing).
Let’s explore these in a little more detail.
Slicing to any grain
Counting minutes played is good because it allows you to rate-adjust your counting stats. Going from goals per game to goals per 90 is a nice improvement. However, inevitably, you will want to go further.
For example, we know that teams set up differently when they are winning or losing, compared to when the scorelines are level. So perhaps you want to adjust for this. Well, to do any adjustments, you need to know how much time was spent at winning, drawing, or losing.
The “find the difference” approach struggles to do this elegantly, and is difficult to extend to multiple such conditions. For example, time played in a given position and while winning.
The windowed approach, on the other hand, can extend to any level of detail just by adding a new condition to divide windows by.
Using the windows
Another nice properties of this approach is that the windows created are a useful asset in their own right.
We already have a way to find the minutes played in a given position. However, what if you wanted to get the individual actions the player made in said position. Or calculate the actions per 90.
Handily, you can use the intermediate windows to fetch the events within them, too.
Easy to translate across data providers
Even if we just wanted to use the simple difference method, there are a few things we need to pay close attention to:
- Injury time
- Extra time
- Red cards and dismissals
- Substitutions and injuries
- Players leaving the field temporarily for physio treatment (if this is recorded at all)
These are are pretty standard concerns, but there are differences between the major providers in how they are represented as part of the event stream. Any method claiming to be the right one for calculating minutes played cannot be tightly coupled to any one provider’s specification.
For this reason, I have talked about this method in rather general, conceptual terms. The key part of applying this method to your specific dataset comes in step 1 and 2 (collating and ordering the events; tagging specific events) when reshaping the data; the operations applied remain the same.
Because the reshaping keeps the data in an event-first structure, it is (in my opinion) both less onerous and more similar across providers than the reshaping required for the simple difference method.
Are there any downsides?
I think any downsides are far outweighed by the benefits of using this method; however, there are a couple of sticking points that you will need to navigate when implementing something like this:
- Inferring missing info (e.g. position) when tracking multiple match conditions. For example, when grouping by player position and scoreline, you will need to infer the players’ positions for events which change the scoreline, since this isn’t part of the base event data. In Postgres, window functions like
first_valueto handle this very well, but it is something to be aware of nonetheless. - Multiple potential start and end-points within the match for each player. In our worked example we had to ignore window #5 because it took place after the player was substituted off. Likewise, if a player leaves the match for whatever reason in the first half, we shouldn’t infer their presence in the second half. Again, window function can handle these permanent entrance/exits well.
That’s all, folks
If you can see any improvements to this, or if you have any better ways of getting the same result, I’d love to hear it. You can let me know on twitter or by email (